XInclude, l’inclusion XML
19/07/2005
L’inclusion de fichier est un problème classique, existant depuis les premiers programmes informatiques, quelle que soit la technologie. Curieusement, les spécifications XML (1.0 et 1.1) n’ont pas abordé cette question. Heureusement cinq années après XML 1.0, XInclude vient combler ce manque. Magazine Login: n°129, juin 2005 – Frédéric Laurent
Les longs fichiers monolithiques ont toujours posé des problèmes. A l’inverse, les fragments de fichier permettent de gagner en robustesse, en simplicité de gestion, en factorisation, en partage d’informations, etc. Si c’est vrai pour les programmes (import java, include en C…), ça l’est également pour les documents. Cinq documents de vingt pages sont nettement plus aisés à maintenir et à faire évoluer qu’un long document de cent pages (surtout dans les environnements collaboratifs).
XML n’est pas épargné par ce problème. En ajoutant des balises permettant d’exprimer la structure d’un document, XML enrichit l’information utile, mais la surcharge. Le document est plus gros et plus long. Pouvoir le découper permet de mieux le maîtriser, de réutiliser et de partager les sous-documents et d’assurer une cohérence qui ne peut l’être en dupliquant la même information dans de multiples fichiers. Les exemples d’utilisation sont légion. Un entête et une information sur des droits d’auteur répétés dans chaque page web XHTML, un livre découpé en plusieurs chapitres, des paramètres généraux inclus dans des fichiers de configuration, etc…

Figure 1 : Inclusion d’un fichier
python dans un document XHTML
Cependant, ce sujet semble avoir été oublié par les spécifications et ne fait donc pas partie du coeur de XML. Plusieurs solutions ont donc été imaginées pour faire des inclusions : par exemple, l’utilisation des instructions de traitement ou des entités externes.
Si les instructions de traitement ont l’avantage de pouvoir être placées à tout endroit du document et de ne pas être intrusives pour la DTD ou le schéma (aucune déclaration nécessaire), elles présentent un inconvénient de taille. Elles demandent un traitement spécifique de la part de l’application qui doit reconnaître l’instruction, la traiter et ainsi gérer l’inclusion du fichier. De plus, le processus de gestion des erreurs est totalement déporté dans l’application, voire inexistant.
Une autre solution, l’utilisation des entités externes, s’est plus largement répandue. Elle se base sur un mécanisme défini par les DTD. Il s’agit de déclarer une entité qui fait référence à un fichier externe, désigné par son URI (voir listing 1). Lors du traitement du fichier XML, le processeur remplacera chaque appel d’entité par son contenu. Le processeur lira donc le contenu du fichier externe désigné et procédera au remplacement de l’appel d’entité.
Cependant, ce système d’inclusion est confronté à de nombreuses limitations. Le document inclus ne peut pas être un document XML bien formé de façon globale, car les déclarations <!DOCTYPE> et <?xml ?>ne peuvent pas être présentes et le document importé peut contenir deux racines. Par ailleurs, il n’est pas possible d’importer un document qui n’a pas une syntaxe XML. L’inclusion d’un fichier java devant figurer dans un document XHTML technique est impossible. Si un problème survient lors du chargement du fichier désigné par l’entité, le processeur provoque une erreur fatale. Aucune gestion des erreurs n’est donc possible. De plus, seule la totalité du document peut être importée. Une inclusion plus fine, c’est-à-dire, une inclusion d’un fragment de document est impossible. Enfin, les entités nécessitent d’être déclarées dans le sous-ensemble interne (voir le listing 1) ou dans la DTD. C’est un processus intrusif qui peut avoir des répercutions désagréables.
<?xml version="1.0"?>
<!DOCTYPE html [
<!ENTITY haut SYSTEM "head.xml">
<!ENTITY bas SYSTEM "tail.xml">
]>
<html>
<head><title>test entite</title></head>
<body>
&haut;
<p>texte du document</p>
&bas;
</body>
</html>Listing 1 : inclusion à l’aide d’entités externes
L’inclusion avec XInclude
XInclude permet de faire l’inclusion d’un document XML entier, d’un fragment de document XML ou d’un fichier non XML. Le mécanisme est très simple. Il se compose de deux éléments : include et fallback. Ces deux éléments sont présents dans un espace de noms qu’il faut déclarer. L’espace de noms http://www.w3.org/2003/XInclude est souvent associé au préfixe «xi», bien que le préfixe ne soit pas important puisque seul l’URI compte. Le listing 2 montre un exemple simple d’inclusion.
<!DOCTYPE html PUBLIC
"-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr"
lang="fr" xmlns:xi="http://www.w3.org/2001/XInclude">
<head><title>test xinclude</title></head>
<body>
<xi:include href="head.xml" mce_href="head.xml"/>
<p>texte du document</p>
<xi:include href="tail.xml" mce_href="tail.xml"/>
</body>
</html>Listing 2 : inclusion grâce à XInclude
L’élément XInclude
Les attributs de cet élément en détail… (lire la suite)
L’élément xi:includedéfinit six attributs : href, parse, xpointer, encoding, accept et accept-language (voir encadré 2). Ils permettent de fournir l’information nécessaire en terme de localisation (du fichier et de la zone réelle à inclure qui peut être une partie du fichier), d’encodage et de négociation de contenu. L’inclusion est récursive. Chaque fragment inclus est analysé à son tour et les inclusions qu’il définit sont traitées. Les inclusions circulaires sont détectées et ne peuvent pas aboutir à un processus infini. XInclude permet d’inclure des données, XML ou non, en les considérant comme non-analysables. Cette fonctionnalité, forte intéressante, permet alors d’intégrer des documents Java, C#, python ou même XML dans un autre document (figure 1). Dans ce traitement spécial, les caractères de balisage sont échappés. Le caractère ‘<’, par exemple, est transformé en < ;
Négociation de contenu
L’inclusion de fichier peut faire intervenir des serveurs HTTP locaux ou distants. Certains offrent une gestion de contenu fine, c’est-à-dire prenant en compte la valeur des paramètres accept et accept-language des requêtes HTTP, et ne se contentent pas de renvoyer la même page quelles que soient ces valeurs. Il s’agit de la négociation de contenu. Selon la valeur de ces paramètres, fixée par le client par le biais de ses préférences, le serveur cherche la représentation de la ressource qui correspond la mieux.
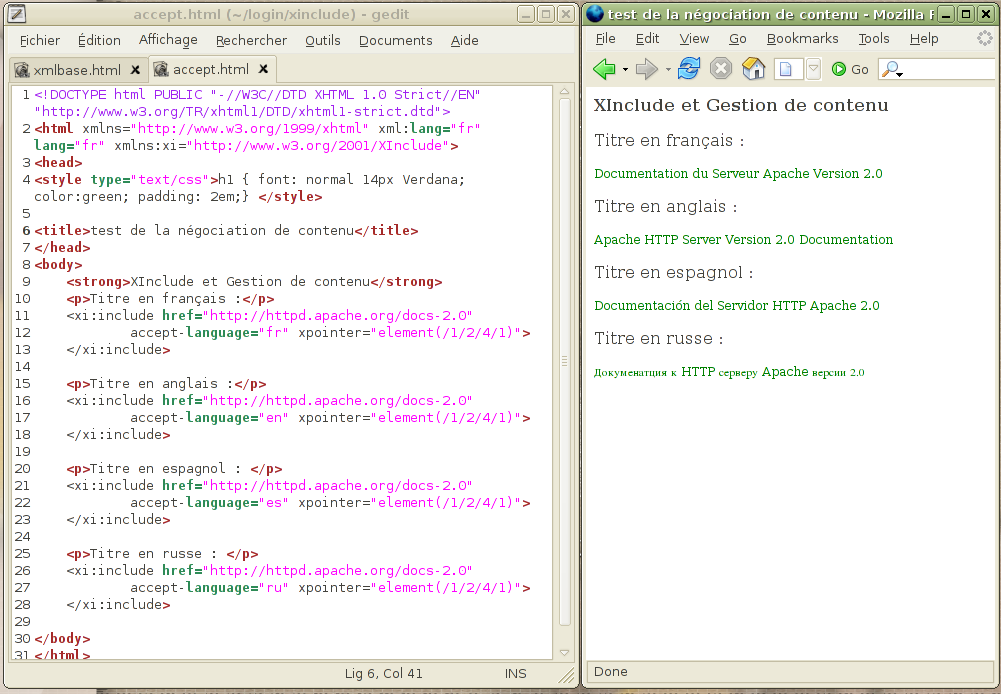
Figure 4 : La négociation de contenu
permet d’obtenir des versions différentes
d’une même ressource
XInclude fait l’analogie avec les en-têtes HTTP, puisque l’expression des préférences en matière d’inclusion se fait par l’ajout des attributs accept et accept-language. Le premier définit le format souhaité de la ressource demandée, c’est-à-dire html, text, xml, etc. Le second permet d’exprimer la préférence quant à la langue, il s’agit d’une valeur ayant la forme, fr-Fr, fr, en-us, etc. Une valeur “fr-fr, en” signifie : je préfère une représentation en langue française utilisée en France, par opposition au français utilisé au Canada par exemple, mais j’accepte aussi toute forme de ressource en langue anglaise. Ainsi, il est possible de demander une version française et html d’une page web ou cette même page dans un format XML et en anglais. Par exemple, le serveur web qui héberge la documentation du serveur apache permet d’utiliser la gestion de contenu. Il délivre un URL différent selon la langue choisie. Dans l’exemple suivant, la page française est demandée:
<xi:include href="http://httpd.apache.org/docs-2.0" mce_href="http://httpd.apache.org/docs-2.0"
accept-language="fr" accept="text/html"/>
La figure 4 montre un exemple plus détaillée d’utilisation de la négociation de contenu avec ce site.
Gestion d’erreur
L’inclusion de document externe est sujette à tous les problèmes de défaillances informatiques classiques. Le fichier peut être absent, il peut être inaccessible en raison d’un échec du réseau, d’un blocage de requête par un proxy, d’une suppression de la ressource par un tiers, ainsi de suite… La possibilité de définir un comportement en cas d’échec de l’inclusion constitue un apport non négligeable de Xinclude. Cette possibilité était une carence de l’inclusion faite avec les entités externes. L’élément xi:fallback permet de spécifier ce comportement. C’est un élément fils de l’élément xi:include. Son contenu sera inséré à la place de l’élément xi:include en cas d’erreur. Le contenu de xi:fallback est libre. Il peut s’agir d’un simple texte, d’un fragment de document ou d’une nouvelle instruction xi:include, comme nous pouvons le voir dans le listing 3.
<body>
<xi:include href="head.xml" mce_href="head.xml">
<xi:fallback>
<xi:include href="errHead.xml" mce_href="errHead.xml"/>
</xi:fallback>
</xi:include>
<p>texte du document</p>
<xi:include href="tail.xml" mce_href="tail.xml">
<xi:fallback>Probleme d'inclusion</xi:fallback>
</xi:include>
</body>Listing 3 : gestion des erreurs
L’inclusion conditionnée par la détection d’erreur est intéressante à plus d’un titre. Imaginons l’inclusion d’un document externe EnteteComplexe.xml (listing 4).
<xi:include href="EnteteComplexe.xml" mce_href="EnteteComplexe.xml">
<xi:fallback>
<xi:include href="EnteteSimple.xml" mce_href="EnteteSimple.xml">
<xi:fallback>erreur d'inclusion du fichier
externe et du fichier alternatif </xi:fallback>
</xi:include>
</xi:fallback>
</xi:include>Listing 4 : inclusion alternative en cas d’erreur
Si celui-ci n’est pas atteignable, un document alternatif, EnteteSimple.xml, sera inclus. Mais s’il ne peut l’être, suite à une nouvelle erreur de localisation du fichier par exemple, on peut imaginer un simple texte laconique, qui sera présent dans le document original et sera donc toujours disponible. Dans tous les cas, la gestion d’erreur est traitée correctement.
L’inclusion partielle
Xinclude permet de faire des inclusions partielles de document. La technologie XPointer permet d’y parvenir. Elle est utilisée à travers l’attribut xpointer de l’élément xi:include. Les processeurs ne sont pas obligés de fournir un support complet de XPointer, seuls le schéma element() et les pointeurs abrégés sont obligatoires. Par ailleurs, certains processeurs, comme celui de libxml ou XInclude.net, offrent la possibilité d’utiliser les schémas xpointer() et xmlns(). Par exemple, l’inclusion ci-dessous permet d’avoir la liste de l’ensemble des documents techniques (Technical Reports ou TR) du W3C, dont le sujet contient RDF :
<xi:include href="http://www.w3.org/TR" mce_href="http://www.w3.org/TR"
xpointer="xmlns(html=http://www.w3.org/1999/xhtml)
xpointer(//html:dt[@class='TR']/html:a[contains(
text(),'RDF')])">
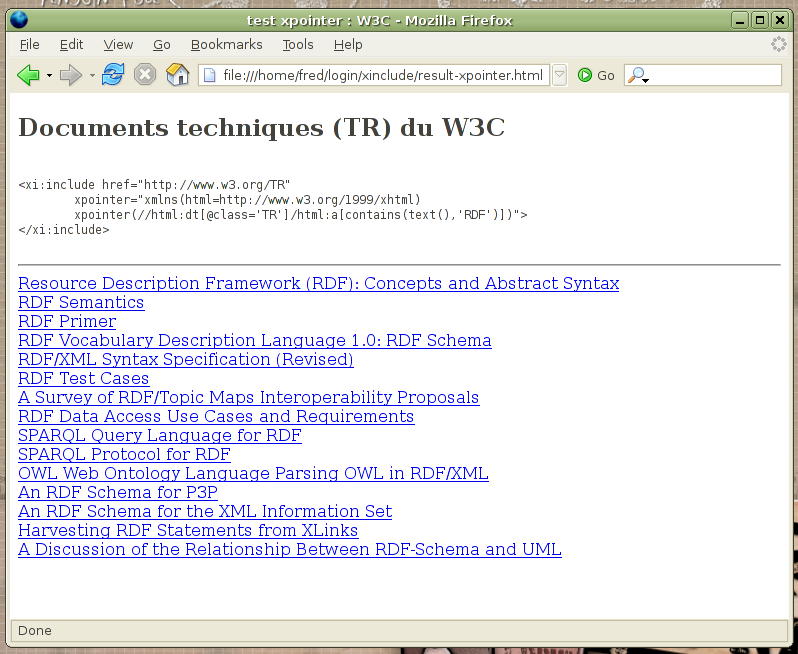
Figure 2 : Inclusion d’un fragment de
document distant en utilisant XPointer
Dans l’attribut xpointer, le schémaxmlns() permet de déclarer l’espace de noms du document référencé. Cet espace de noms sera utilisé pour localiser l’information dans le schéma xpointer(). Le contenu du schéma xpointer est une expression XPath, dont une version française pourrait être : “toutes les balises <a> qui ont pour élément père une balise <dt>, dont l’attribut class vaut TR, et dont le contenu textuel (de la balise <a>) contient le texte RDF” (figure 2).
Support de xml:base
XInclude utilise la spécification du W3C xml:base. Le processeur XInclude positionne l’attribut xml:base sur la balise racine du fragment inclus, de sorte que chaque lien relatif, contenu dans le fragment, soit correct. Ainsi deux liens vers doc.xml ne pourront pas être confondus car ils seront relatifs à l’URL spécifié par leur attribut parent respectif. Par exemple, l’incorporation de la liste des technologies proposées par le W3C ne pose pas de problème relatifs aux liens hypertextes, grâce au positionnement d’un attribut xml:base. Les liens ne sont pas modifiés (<a href="/amaya/" mce_href="/amaya/">Amaya</a>) et l’URL est correct car il est chapoté par une déclaration xml:base permettant de construire le lien cible (voir figure 3).
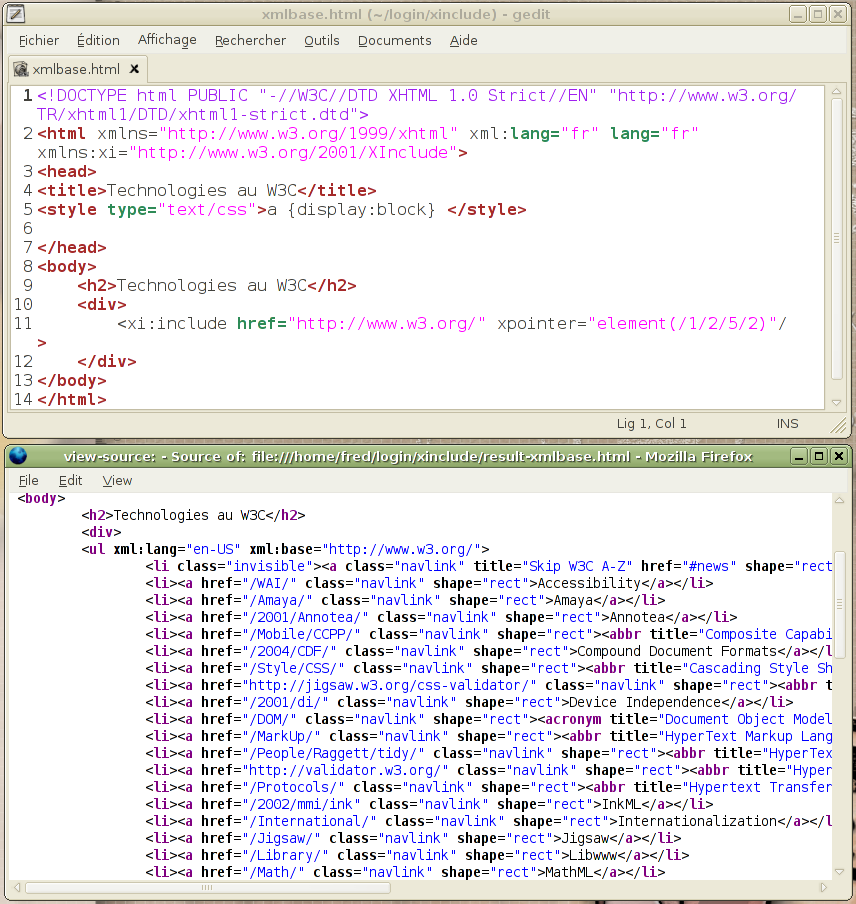
Figure 3 : Le processeur insère un attribut
xml:base rendant les URL consistants
xml:base peut également être utilisé par le document faisant l’inclusion. Les inclusions seront alors spécifiées relativement à cette base, évitant de ressaisir les URI complets. Cette facilité apporte non seulement de la lisibilité mais aussi de la robustesse car le risque d’erreur dans les URI est diminué.
<doc xml:base="http://www.site.org/mondocument">
<xi:include href="chapitre1.xml" mce_href="chapitre1.xml" />
<xi:include href="chapitre2.xml" mce_href="chapitre2.xml" />
<xi:include href="chapitre3.xml" mce_href="chapitre3.xml" />
</doc>
Quelques limitations
Malgré ses nombreux atouts, XInclude présente quelques désagréments. Cette spécification a pris pas de moins de cinq années pour voir le jour. Ce temps extrêment long dans le domaine des formats XML, a vu éclore nombre de spécifications ne prenant pas en compte XInculde, jugé dans un état instable. Ainsi les définitions de schémas (DTD, XML Schémas, schémas RelaxNG, etc) ont fait l’impasse sur XInclude et cela vient perturber la validation. Il faut en effet déclarer l’espace de noms XInclude pour permettre au processeur de traiter les balises d’inclusion, mais cette déclaration reste dans le document après la transformation. Une spécification XHTML, même récente, ne s’attend pas à trouver une déclaration xmlns:xi="http://www.w3.org/2003/XInclude" sur sa racine.
Support de XInclude
De nombreux processeurs mettent déjà en œuvre XInclude mais de façon très inégale (lire la suite)
Le document, après inclusion sera donc invalide. L’ajout par le processeur de l’attribut xml:base pose le même type de problème. Plusieurs solutions sont envisageables. On peut imaginer de ne pas valider le document résultant, de modifier les grammaires pour prendre en compte ce genre d’information ou encore de définir au niveau même de XML, que les attributs xmlns ou xml:* peuvent être présents à tout endroit dans un document et ne doivent pas être pris en compte par la validation. Quoi qu’il en soit, cet inconvénient risque de prendre du temps avant qu’il ne soit totalement résolu.
Une option à explorer
XInclude vient remplacer l’utilisation délicate des entités externes. Cette nouvelle spécification comble ainsi un manque important dans l’espace XML et formalise un mécanisme d’inclusion robuste, qui utilise les concepts XML fonctionnant par ailleurs (élément, URI, espace de noms, xml :base). Même si certains questions restent posées, notamment sur la post-validation, et que la mise en oeuvre de cette spécification par les processeurs est aujourd’hui disparate, XInclude repésente une avancée vraiment intéressante pour les documents orientés données. Le développement rapide de cette technologie permet d’envisager à terme un support natif par les navigateurs Internet, fournissant alors la possibilité de faire des inclusions dans les pages XHTML.
Les sources de l’article
- XInclude avec XOM : TestInc.java
- test de accept : xi-accept.html
- test de xpointer xi-xpointer.html