Analyse des données Finess publiées en Open Data
08/08/2016
Les données Finess font partie des référentiels des Systèmes d'Information Hospitalier. Elles sont disponibles sur le portail Open Data du Gouvernement. Ce billet propose une analyse de ce jeu de données et des propositions d'amélioration.
Le Fichier National des Etablissements Sanitaires et Sociaux constitue la liste des établissements et entités juridiques porteurs d'une autorisation ou d'un agrément. Ces données sont gérées par la DREES du ministère de la Santé. Depuis plusieurs années, elles sont accessibles sur le site dédié du ministère et sur la plateforme OpenData du gouvernement.
Outre les nouveaux usages possibles avec la mise à disposition de ces données dans le cadre de la démarche Open Data, ces données sont, aussi et surtout, des données de référence pour les Sytèmes d’Information Hospitalier.
Nous verrons :
- Quelle utilité ont ces données dans le SIH ;
- Les problèmes d’accès ;
- La qualité des données ;
- Quelles propositions pour améliorer leur utilisation.
Utilité des données dans le SIH
La liste des établissements sanitaires et sociaux est l'un des jeux de données fondamentaux du Système d’Informations Hospitalier. Ce sont des données de référence présentes dans de nombreux logiciels. Elles servent non seulement au fonctionnement interne des établissements mais également dans la majorité des échanges d'informations avec les partenaires exterieurs, qu’il s'agisse d’échanges à visée médicale ou économique.
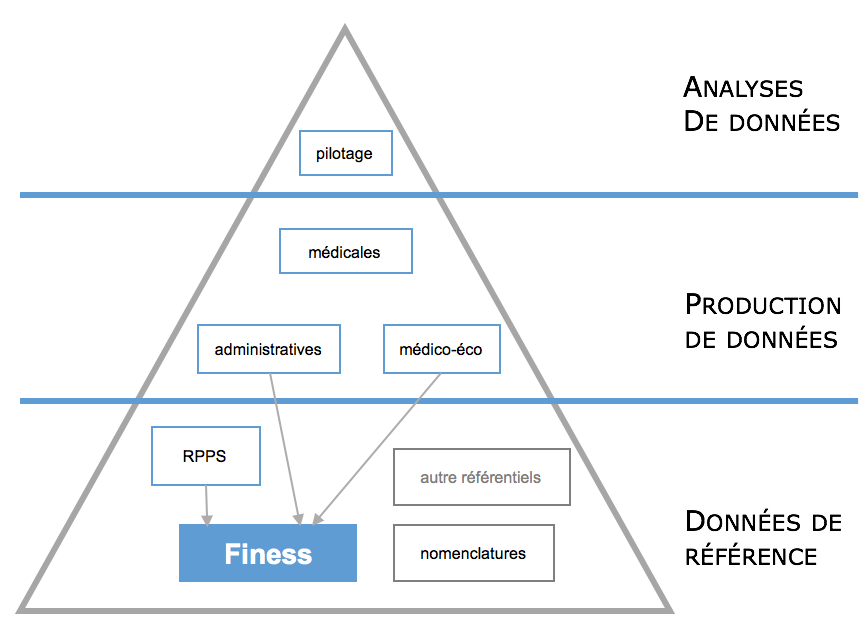
Elles sont notamment nécessaires :
- pour renseigner le parcours (se soins) du patient au sein du SIH : sa provenance, sa destination ;
- pour produire les fichiers, envoyés aux tutuelles, à l’assurance maladie, permettant le financement des établissements (norme B2, fichier RUM du PMSI) ;
- pour référencer le lieu de pratique des médecins exerçant dans les établissements : les prescripteurs, les médecins référents, les spécialistes, etc. Ces identifiants de structure sont utilisés dans le RPPS, le Répertoire des Professionnels de Santé, qui constitue lui aussi un ensemble de données fondamental pour le SIH ;
- dans le cadre des échanges d'informations médicales. Le finess est utilisé dans les différents volets du Cadre d’Interopérabilité des Systèmes d’Information de Santé (CI-SIS), défini par l’ASIP Santé.
Problème de la mise à jour des données Finess
L’importance de ces données devrait guider une mise à disposition, sinon en temps réél, du moins quotidienne. Le site Finess du ministère de la santé, précise que ces données sont effectivement mises à jour quotidiennement. Malheureusement, leur mise à disposition n'est que trimestrielle ! Il s'agit en effet une extraction de la base Finess. Nous sommes donc face au paradoxe de données de référence volatiles mais communiquées 4 fois par an.
En analysant, les données, il est en effet simple de constater le nombre important et régulier de mises à jour :
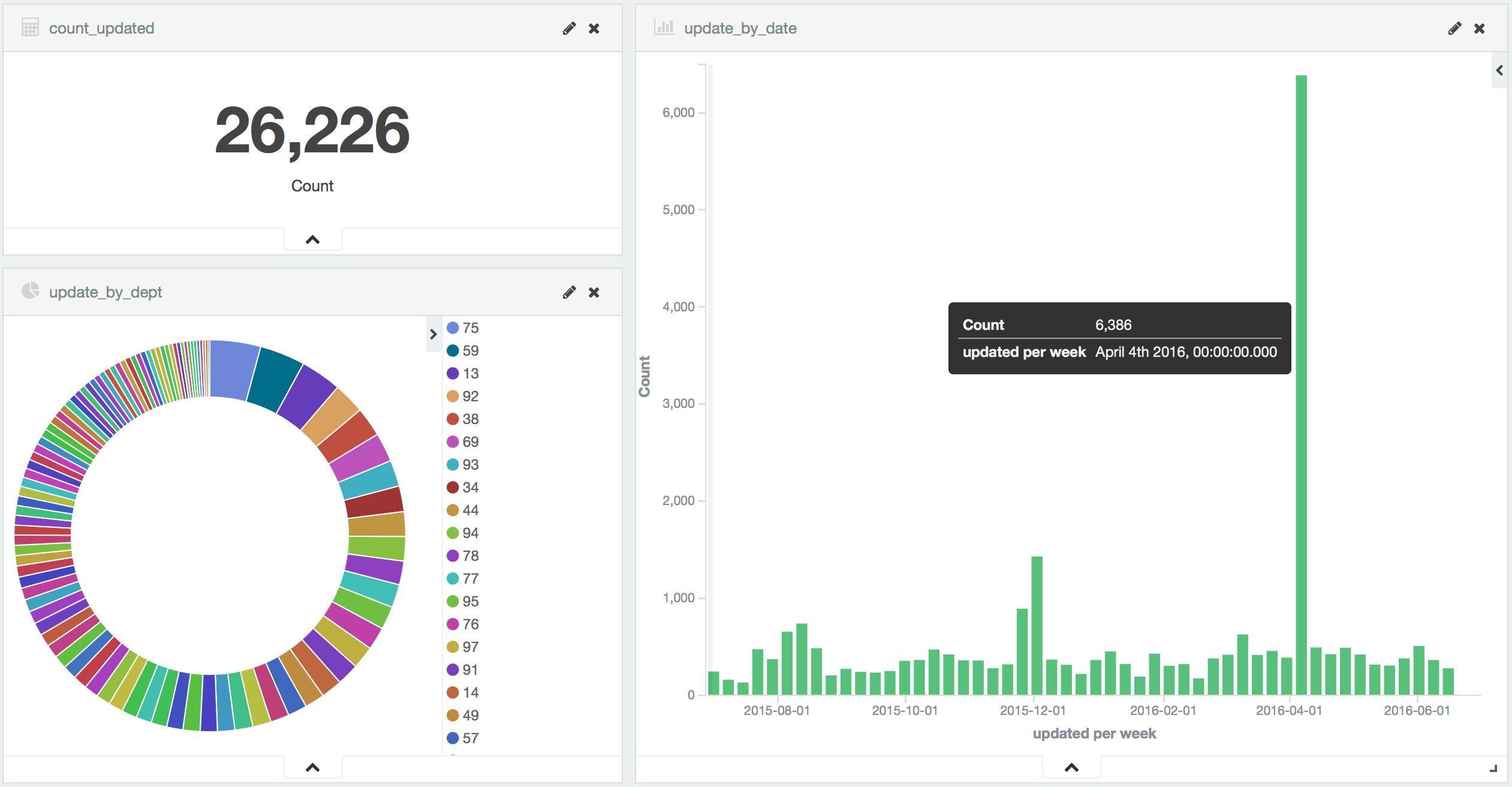
Ce sont plus de 26000 mises à jour qui ont eu lieu en 2016.
Par ailleurs, on peut noter que le pic de mises à jour d'avril 2016 survient après la publication du premier trimestre, le 18 mars 2016, et avant la publication du second trimestre, le 20 juin 2016. Il est donc nécessaire d'attendre 11 semaines pour obtenir la mise à jour de plusieurs milliers d'établissements.
Un zoom sur une période classique de 2 mois (sans pic) montre que ce sont plus de 4300 mises à jour régulières qui sont faites et qui doivent attendre la prochaine extraction pour être intégrées dans les Systèmes d'informations.
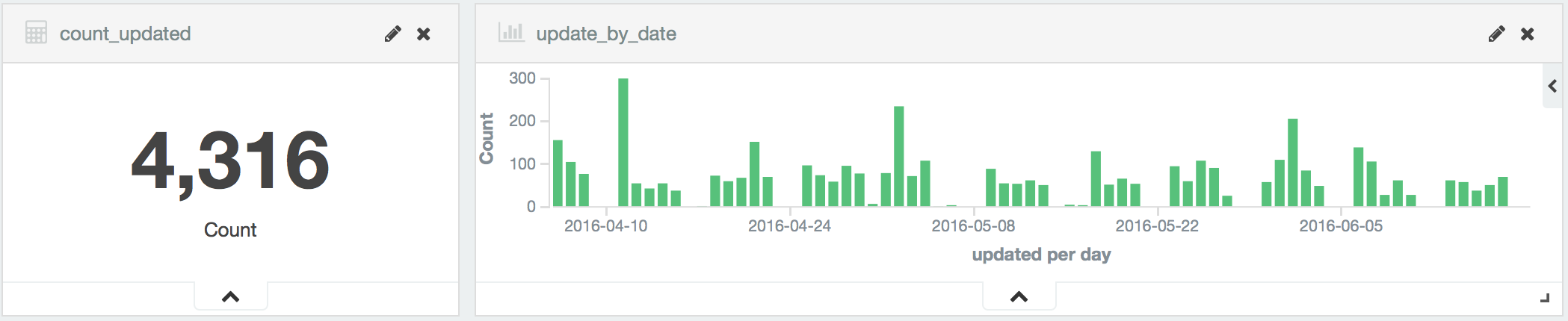
Par ailleurs, la souscription au suivi sur le portail data.gouv.fr n'a jamais remonté d'alerte sur le sujet. Il est donc du ressort de l’utilisateur de surveiller par consultations régulières la mise à jour des données, qui sont donc par définition constamment obsolètes.
Enfin, si une date de mise à jour est positionnée dans l'extraction, aucun moyen permettant de savoir si une structure est fermée n'est proposée. La structure disparait tout simplement de l’extraction : charge à l’utilisateur des données de gérer le différentiel entre deux situations puis de déduire qu’une structure absente est une structure fermée. Et malheureusement, la véritable date de fermeture n’est pas connue. Ce qui conduit inévitablement à avoir dans les SIH des informations fausses, c'est-à-dire des informations en relation avec des structures fermées, mais qui ne l'étaient pas au moment de la saisie.
La remarque sur le problème posé par le cycle de rafraichissement a déjà été faite sur le site www.data.gouv.fr. Elle date de janvier 2015, soit plus d'un an et demi. Cependant, cette remarque n'a pas été prise en compte. La remarque concernant le problème de la date de fermeture a également été faite, mais aucun changement n'est prévu.
Qualité des données
Le site du ministère de la santé renvoie sur le site Open Data du Gouvernement pour les données et leur description.
Les données sont fournies sous forme d’une extraction CSV. Par contre, la description des données est faite via la fourniture d’un document PDF décrivant un format XML au travers de la fourniture d’un schéma XSD.
Plusieurs questions viennent naturellement :
- si le document PDF décrit une structure XML, pourquoi fournir une extraction CSV ?
- pourquoi la documentation n’est pas cohérente avec les données (commentaire de janvier 2015 sur data.gouv.fr, toujours non résolu) ?
- pourquoi fournir un schema XSD dans un document PDF et non dans format texte pour qu’il soit exploitable par un système informatique ?
- si le fichier de description est fourni en PDF, pourquoi ne pas mettre les contraintes sur les types et les longueurs en clair dans le tableau, plutôt que devoir déduire du schéma XML les contraintes s’appliquant aux données ?
Les données au format CSV ne peuvent pas être validées avec le schéma XSD fourni. Un programme est donc nécessaire pour vérifier la validité des données. L'analyse révèle quelques erreurs :
Col 15 -> ligneacheminement = Ligne d'acheminement (CodePostal+Lib commune) (min= 1, max=26) : 4123 errors = 4.41%
Mais on constate également que de nombreuses zones sont vides
Col 5 -> Complement de raison sociale : 84116 empty values = 89.91% Col 6 -> Complement de distribution : 80377 empty values = 85.92% Col 7 -> Numero de voie : 21858 empty values = 23.36% Col 8 -> Type de voie : 8941 empty values = 9.56% Col 9 -> Libelle de voie : 5227 empty values = 5.59% Col 10 -> Complement de voie : 90597 empty values = 96.84% Col 11 -> Lieu-dit / BP : 83128 empty values = 88.86% Col 16 -> Telephone : 12247 empty values = 13.09% Col 17 -> Telecopie : 43178 empty values = 46.15% Col 22 -> Numero de SIRET : 14887 empty values = 15.91% Col 23 -> Code APE : 53200 empty values = 56.87% Col 26 -> Code SPH : 82848 empty values = 88.56% Col 27 -> Libelle SPH : 82848 empty values = 88.56% Col 29 -> Date d'autorisation : 488 empty values = 0.52% Col 31 -> Numero education nationale : 89849 empty values = 96.04%
Propositions
Les données que contient ce fichier Finess sont très importantes pour l’utilisation quotidienne dans un SIH. Même si ce fichier est désormais présent en Open Data et donc plus accessible qu’auparavant, il reste plusieurs points à améliorer pour qu’il soit vraiment utilisable de façon efficiente :
- fournir en temps réel ou quotidiennement des données à jour ;
- prévenir de la mise à jour de ce fichier de façon à ce qu’un programme informatique puisse l’intégrer dans un processus de mise à jour : par exemple, fournir un flux Atom ou toute autre technologie pub/sub ;
- incorporer les dates de fermeture des structures pour que les SIH aient des données cohérentes ;
- fournir un couple format de données/documentation cohérent. La meilleure évolution serait évidemment de fournir un schéma XSD dans un format texte et un fichier de données XML valide par rapport à ce schéma ;
- compléter les données vides ;
- dernière proposition, plus complexe, mais qui devrait être de facto pour des données de référence : fournir un code system identifiant de manière unique les numéros finess gérés par le ministère de la santé. Ce code system peut être une URL ou un OID et le couple code system/<numéro finess> serait alors unique et non ambigu.
Code pour l'analyse et les visualisations
Les visualisations sont réalisées à l'aide de Kibana. Un programme python analyse les données CSV et les publie dans ElasticSearch. Le tout est mis en oeuvre de façon simple à l'aide des images Docker du Docker Hub.
Pour lancer l'analyse, il suffit de cloner les sources depuis github, de lancer docker et le programme python.
Le fichier de données, 30Mb, n'est pas dans le repo github, il suffit de le télécharger sur la plateforme opendata.gouv.fr : Extraction du Fichier National des Etablissements Sanitaires et Sociaux (FINESS) par établissements.
$ git clone http://github.com/flrt/opendata-finess $ docker-compose -f docker-compose-elk.yml up -d $ python etalab_finess.py data/etalab_cs1100502_stock_20160620-0437.csv
L'interface Kibana est accessible à l'adresse : http://localhost:5601/
Pour obtenir le type de visualisations supra, il suffit de charger les deux fichiers de
configuration des visualisations et du tableau de bord : kibana_vizualisations.json et
kibana_dashboards.json.